Authored by Tony Feng
Created on Oct 20th, 2022
Last Modified on Oct 25th, 2022
Intro
This sereis of posts contains a summary of materials and readings from the course CSCI 1460 Computational Linguistics that I’ve taken @ Brown University. The class aims to explore techniques regarding recent advances in NLP with deep learning. I posted these “Notes” (what I’ve learnt) for study and review only.
What is pretraining?
- Train on some “general” task that encourages good representations
- Transfer these representations with little updating to other tasks
- No need to train embeddings anew for every task
Contextualized Word Representations
Basic Idea
Traditional word embedding methods (e.g., word2vec) produce typelevel representations, while contextualized word embeddings (e.g., BERT, ELMo) produce token-level representations.

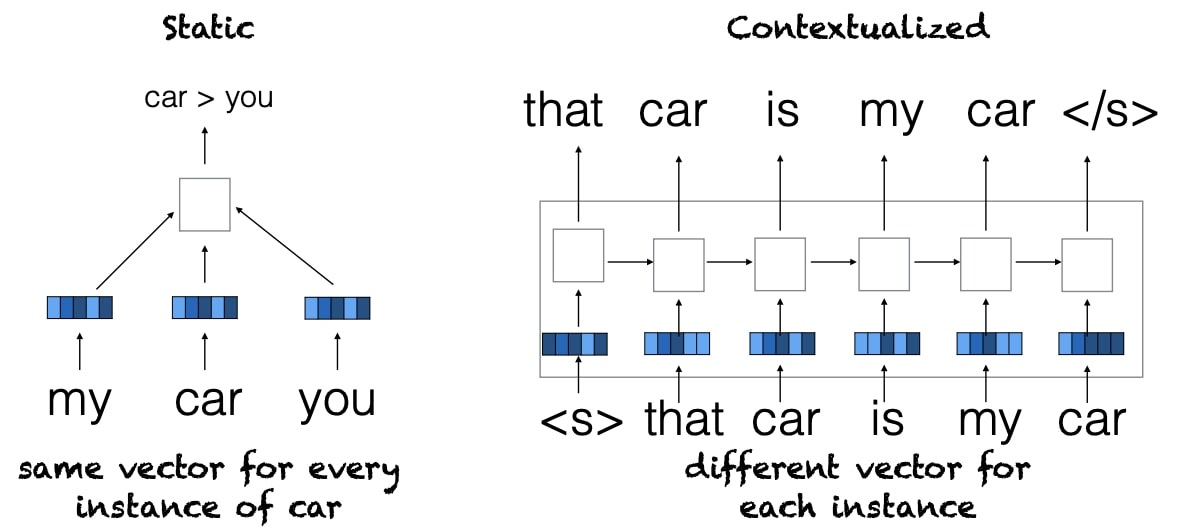
Advantages
- It can capture word sense
- It can capture syntactic and semantic context
Disadvantages
- Variable-length sentence representations
- No clear “lexicon”, which (traditionally) linguistics likes to have
- More training data needed
ELMo
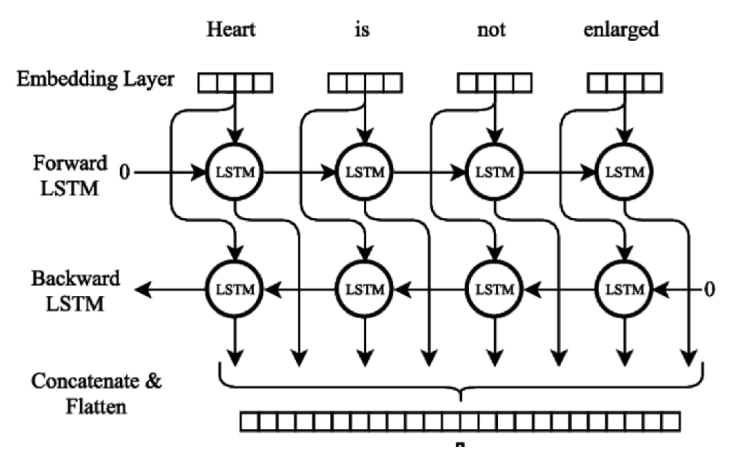
- Architecture: Two-layer BiLSTM
- Layer 0 = pretrained static embeddings (Glove)
- Trained on vanilla language modeling task
- Finetuned by learning a simple linear combination of the learned embeddings
BERT
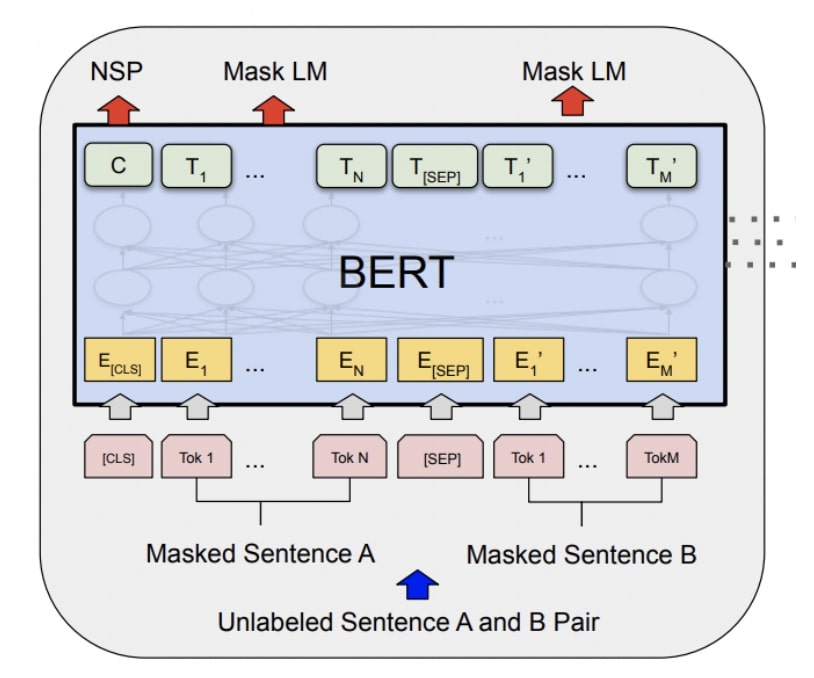
- Architecture: Deep Transformer (small = 12, large = 24)
- Layer 0 = wordpiece embeddings
- Trained on masked language modeling + next-sentence prediction
- Typically finetuned by updating all parameters (though there are other strategies)
GPT
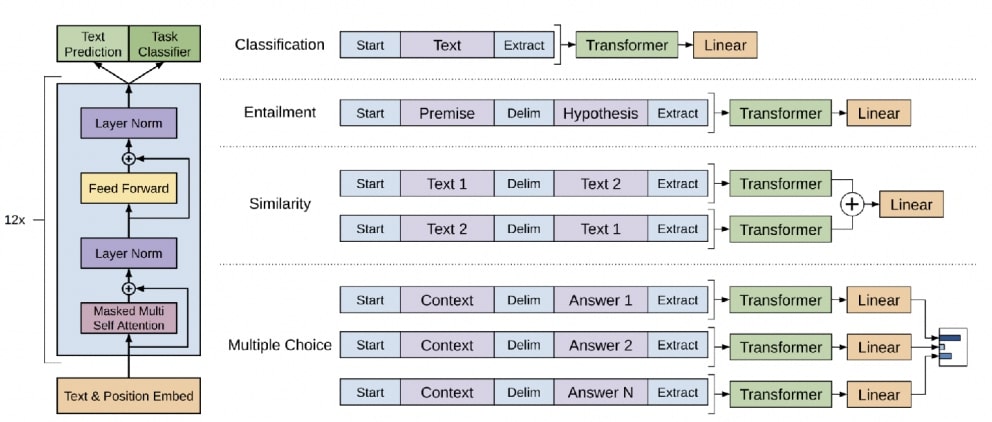
- Architecture: Deep Transformer
- Layer 0 = BPE
- Trained on vanilla language modeling
- Notable because the recent versions (GPT-3) are HUGE, and very impressive
- Typically finetuned by updating all parameters (for the small models) or (for the large models) prompting
Different Transfer Methods
Frozen
Just pool representations and train a new classifier on top。
Finetuning
Treat pretraining as a good initialization and continue to update all parameters on new tasks. Models perform better and require less data to learn the target task.
“Prompt” Tuning
Update a small number of parameters at the bottom of the network.
Adapters
Update a small number of parameters throughout the network.
Zero-Shot or “In-Context” Learning
Cast all tasks as an instance of the task that the model was trained on (e.g., language modeling).
- Results are high variance, depending on exact wording of the prompts.
- Unclear what was seen during training, so hard to know how much they are truly learning and generalizing vs. parroting.