Authored by Tony Feng
Created on Sept 20th, 2022
Last Modified on Sept 20th, 2022
Intro
This sereis of posts contains a summary of materials and readings from the course CSCI 1460 Computational Linguistics that I’ve taken @ Brown University. The class aims to explore techniques regarding recent advances in NLP with deep learning. I posted these “Notes” (what I’ve learnt) for study and review only.
Data Pre-processing
Preprocessing VS. Features
Preprocessing: Defining the vocabulary
Features: Capturing the aspects of the language that is independent
Differences in steps
- Load the data
- Preprocess the data
- Extract the features
- Split the data
- Train and test the model
Preprocessing Steps
- Strip boilerplate/html/etc
- Tokenization
- Stemming/Lemmatization
- Lowercasing
- Removing punctuation, stop words, numbers, etc.
- Setting a Vocab Size/Defining out-of-vocabulary (OOV)
- Word Sense Disambiguation (one word with multiple meanings)
- Combining Synonyms/Paraphrases
Feature Engineering
Weighting Strategies
Basic BOW: 0 and 1 for appearance
Count: Frequency in a document
TF-IDF: Weighting schemes for important words
TF-IDF is about assigning higher weights to words that differentiate this document from other documents. More info could be find here.
TF(word, doc) = # of occurrences of the word in the doc / # of words in the doc
IDF(word) = log(# of all docs / # of docs that contain the word)
TF-IDF(word, doc) = TF(word, doc) * IDF(word)
You could try TF-IDF Demo here.
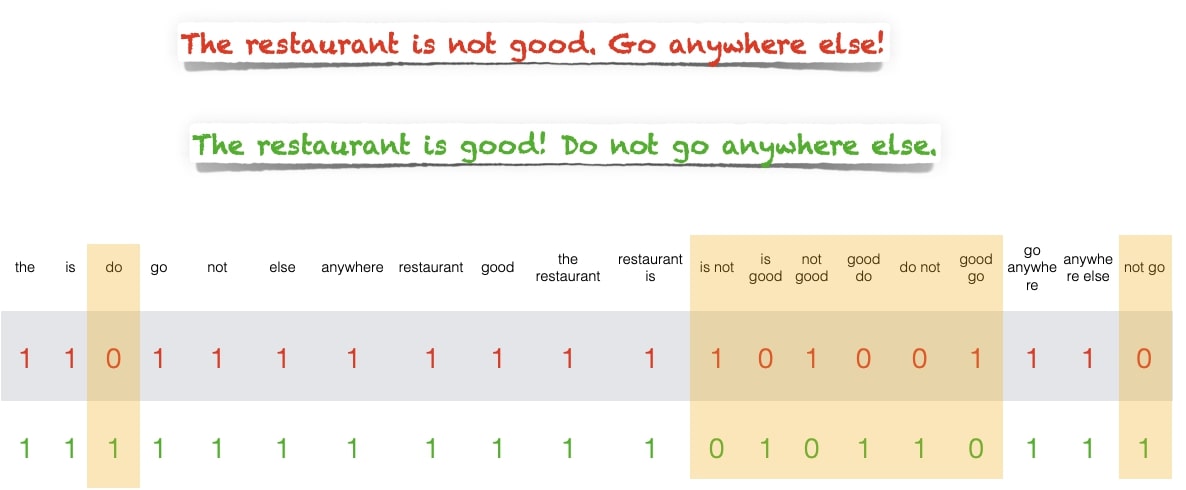
N-Grams
N-gram is a sequence of words of lenght N, such as unigram, bigram, trigram, 4-gram, etc. The algorithm uses sliding window with N length to extract features.
However, it may lead to large feature space. It’s a tradeoff between expressivity and generalization.
More Advanced Features
Syntactic Features
People often use dependency parsers to find meaningful links between non-adjacent words