Authored by Tony Feng
Created on Sept 22nd, 2022
Last Modified on Sept 22nd, 2022
Intro
This sereis of posts contains a summary of materials and readings from the course CSCI 1460 Computational Linguistics that I’ve taken @ Brown University. The class aims to explore techniques regarding recent advances in NLP with deep learning. I posted these “Notes” (what I’ve learnt) for study and review only.
Morphology
Why can’t we just split on white space?
- Compounding
- Many language systems don’t use white space
- Clitics
- Words formation
Finite State Machines
This is the main rule-based computational tool for morphological parsing in NLP.
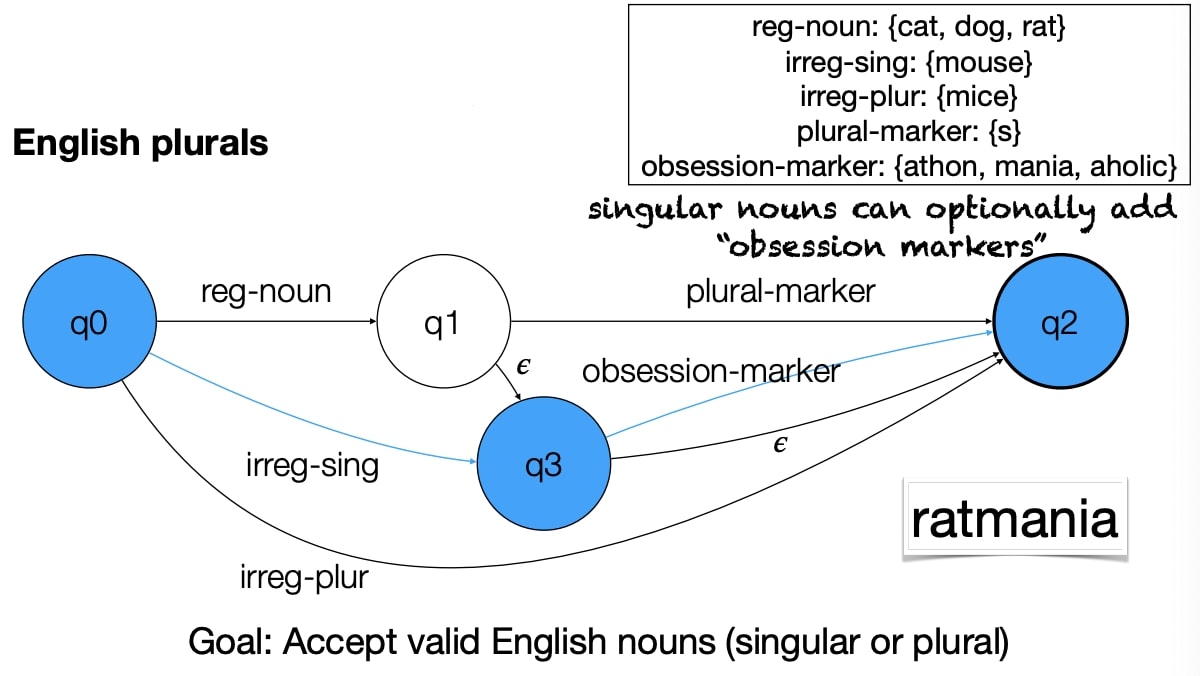
Finite State Automata (FSA)
It is used to check whether to ‘accept’ a string.
Formal Definition
- A finite set of states: $ \mathrm{Q}={q_{0}, q_{1}, \ldots q_{N-1} } $
- A finite set of symbols (alphabet): $ \Sigma={i_{0}, i_{1}, \ldots i_{{M}-1}} $
- A start state & Final States
- A transition function that returns the new state, given a state and a symbol: $ \delta(q, i) $
Psuedocode for Implementation
|
|
Non-Determinism
- Multiple links out of the same node
- Epsilon transitions
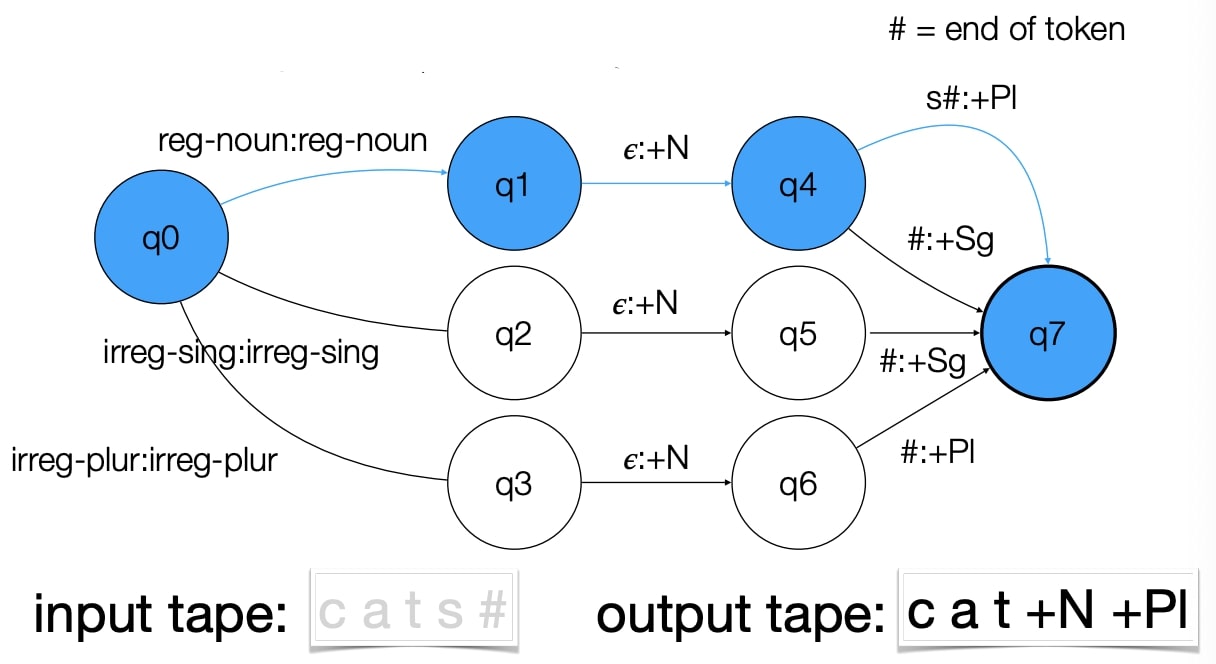
Finite State Transducer (FST)
It is used to ’translate’ one string into another, which produces a parse as output.
Subword Tokenization
Subword Tokenization is a way to algorithmically identify common sub-sequences of characters and merge them into atomic units.
Problems
Tokenizers result in many unknown words (OOVs), and morphological analysis can help, but:
- Running morphological analyzers is expensive and language specific
- Rare words might be “guessable” from cues
Byte Pair Encoding
Steps
- Break words into characters
- Define a number of iterations to run
- Count the frequency of all pairs of symbols
- Merge the most frequent pair of characters, treating them as a new token
- Repeat
- Tp parse new inputs, just apply merge in order